

推荐系统的“前身”
2016年,腾讯以80亿美元估值投资今日头条,结果大家都知道,张一鸣拒绝了腾讯的投资,现在大家也知道,字节跳动估值750亿美元,这一切,推荐系统功不可没。
因为搜索引擎和推荐系统太相似,相对来说也更简单(勿喷),所以我们先来了解一下搜索引擎。至于搜素引擎是不是推荐系统的前身,我很懒,没有考察。
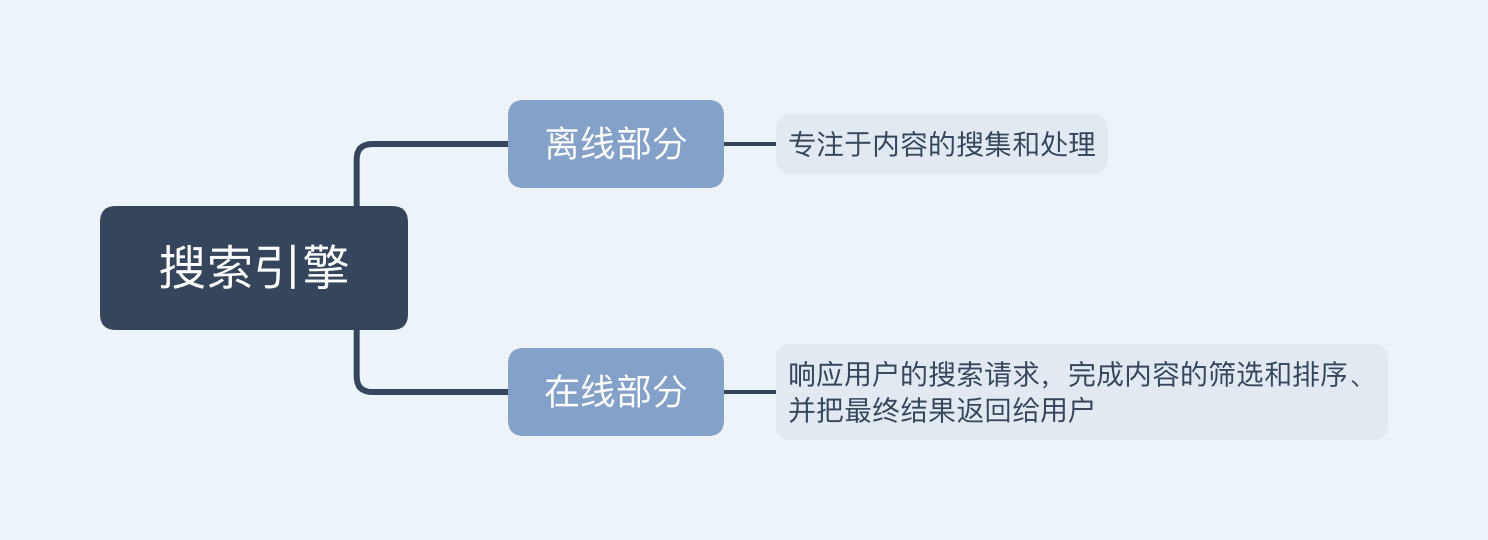
如上图,搜索引擎分成为离线部分和在线部分,每一部分有不同的使命。
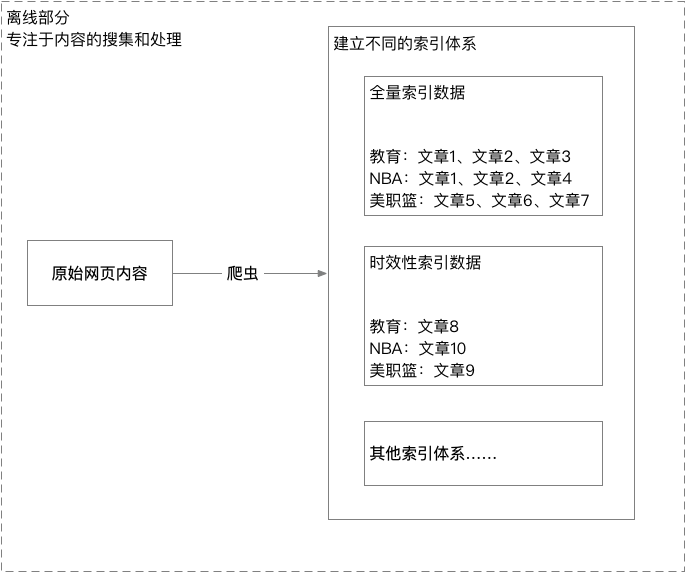
简单来说,搜索引擎的离线部分,专注于内容的搜集和处理。搜索引擎通过网络爬虫抓取网站上的原始内容,并将内容建立索引。这些内容会根据搜索系统的不同要求建立不同的索引体系,比如新闻类型的内容,会建立时效性的索引数据。
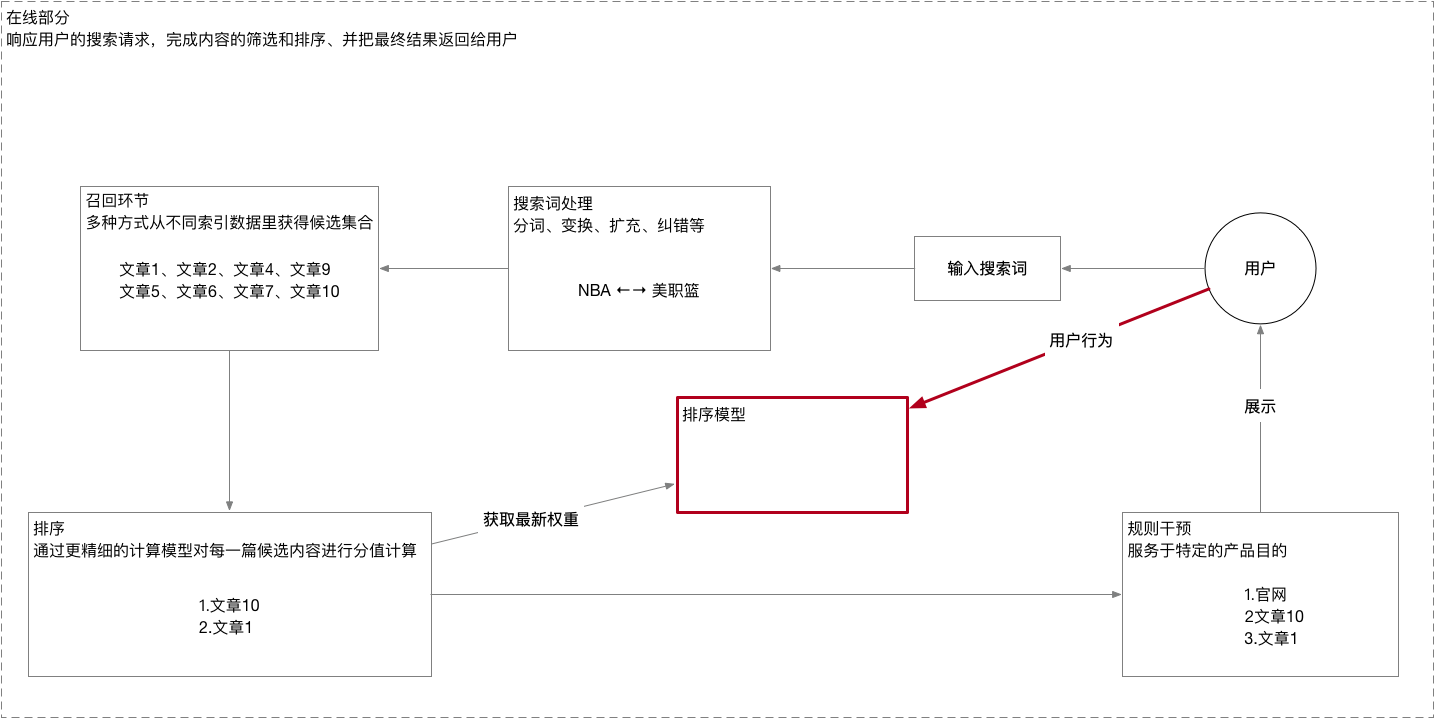
搜索引擎的在线部分,负责响应用户的搜索请求,完成内容的筛选和排序,并将最终结果返回给用户。我们举一个例子来说明这个流程:
用户在搜索引擎输入一个关键词NBA,搜索引擎搜索会对关键词进行分析、变换、扩充和纠错等处理,比如发现美职篮与NBA是同义词,就会将其扩充。接下来,搜索引擎会通过多种方式从不同索引数据获得候选集,这个环节叫召回。得到候选集后,搜索引擎通过更精细的计算模型对每一篇候选内容进行分值计算,对候选集的每一项进行排序。这个时候,还不能将结果展示给用户,需要经过规则干预这一过程。这个过程服务于特定的产品目的。假如有这样一条“官方网站保护规则,确保所有品牌搜索词都可以优先返回官网”,则此时就会将官网插入并置顶,最后再将结果展示给用户。此时,搜索引擎的工作还未结束。搜索引擎会根据用户的点击反馈去优化排序模型。比如,大部分用户都没有点击文章10,则文章10后续就不会获得更靠前的展现位置。
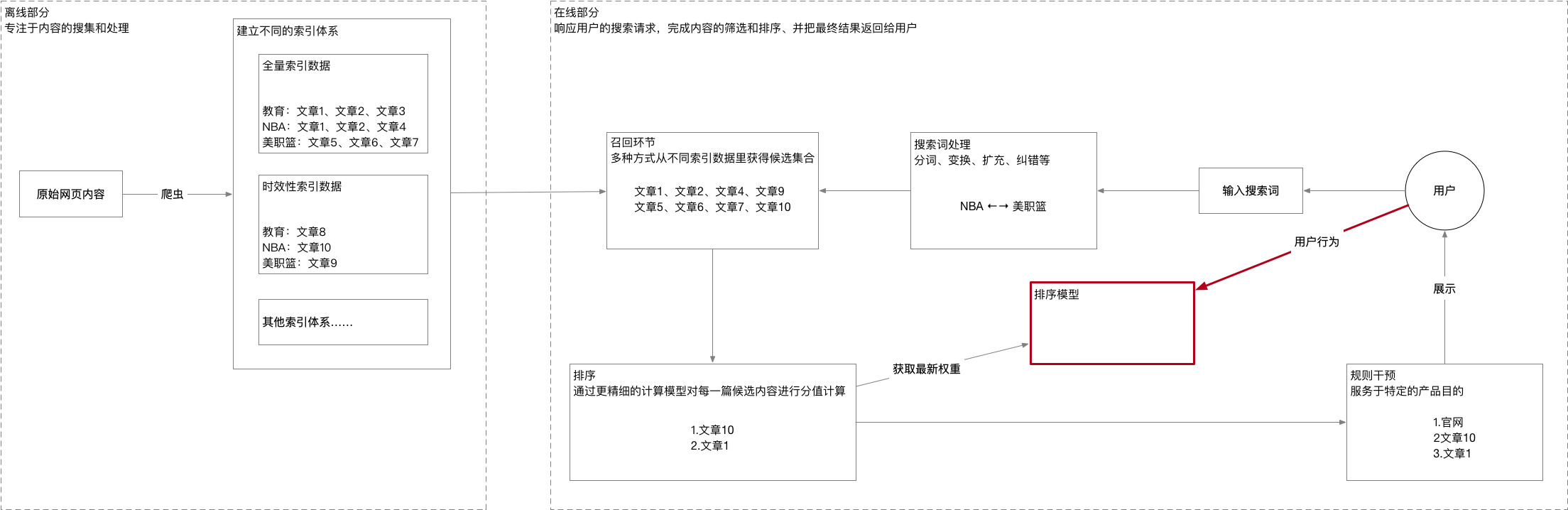
对以上两图进行总结就是下图,就是想让你们看的第一张图:
今日头条的推荐系统
通过上“一”张图,我们明白了搜索引擎的原理(无论怎样我都会装作你看懂了),而今日头条的这张图,就是比上图上多了一笔,考虑到这两张图高度相似,我这么懒的人,当然是不会去画的了,你们发挥想象吧。
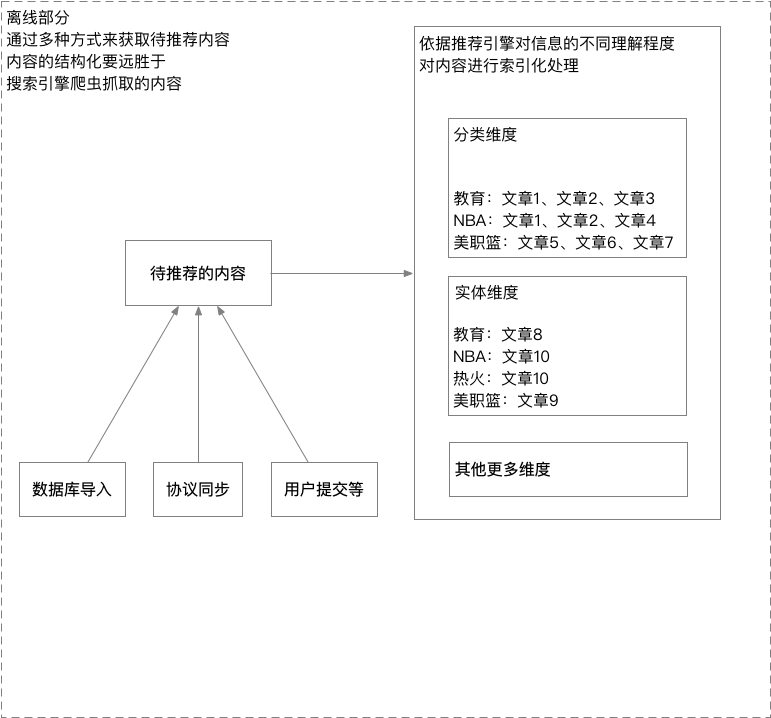
其实,推荐系统也有离线部分和在线部分。上图(那不是图,是PNG)即是推荐系统的离线部分,与搜索引擎大同小异。
和搜索引擎一样,推荐系统也需要获取内容。推荐系统通过数据库导入、协议同步和用户提交等方式获取推荐内容。区别于搜索引擎,推荐系统获取内容的方式较多,且内容的结构化程度要远胜于搜索引擎爬虫抓取的内容。推荐系统也需要将待推荐的内容进行索引化处理,这一点与搜索引擎较为相似。推荐系统的维度会更多。
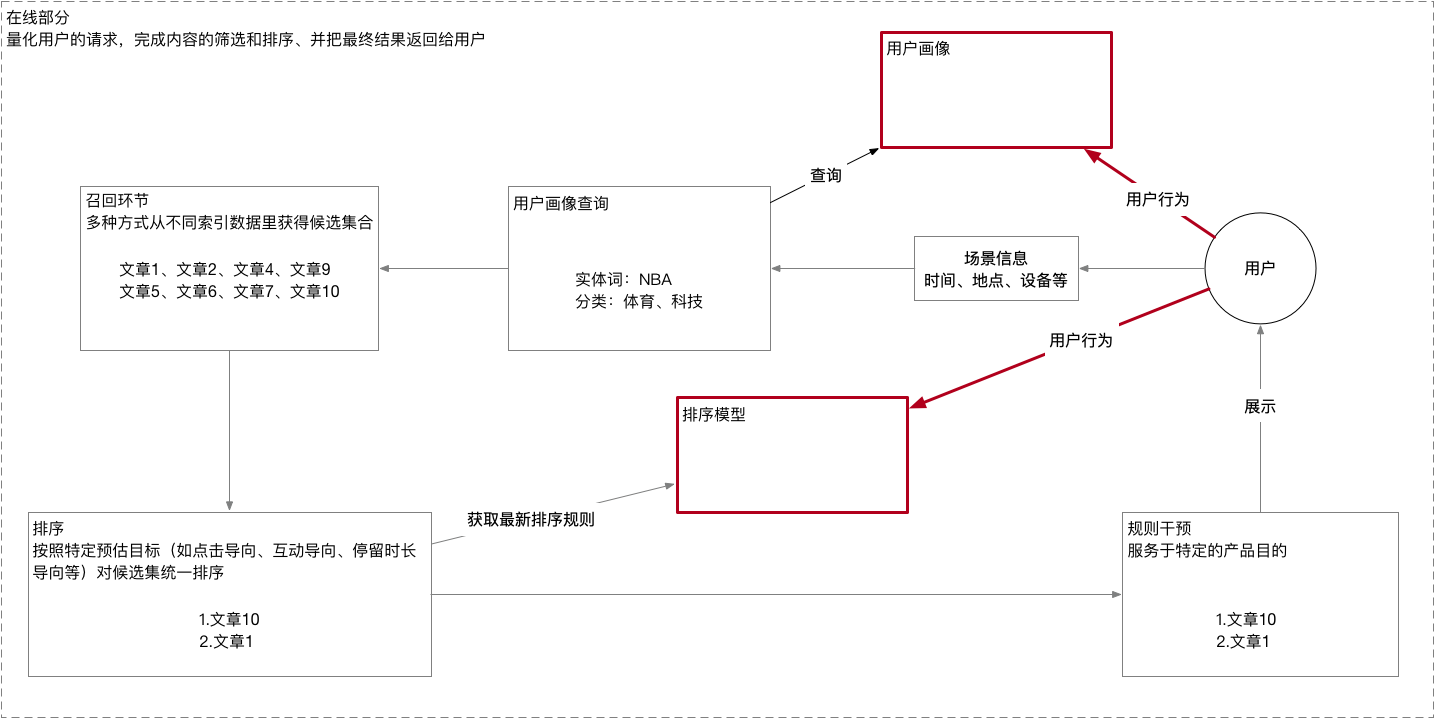
接下来,就是推荐系统的在线部分了。天啊,看到上图,发现推荐系统真的和搜索引擎太像了,就多了一笔。
搜索引擎的输入为用户的搜索关键词,推荐系统同样需要输入,只是这个过程用户没有感知,对推荐系统来说,它的输入为场景信息,比如时间、地点和设备等。搜索引擎获得输入后,会进行关键词处理,对于推荐系统来说,会进行用户画像查询。这个案例中,推荐系统了解到,该用户在实体词维度,对NBA感兴趣,在分类维度,对体育和科技感兴趣。查询到用户画像后,推荐系统就进入召回环节。它通过多种方式,根据用户画像查询结果“NBA、体育和科技”,从不同索引数据里获得候选集合。在召回完成后,和搜索引擎一样,推荐系统按照预定预估目标对候选集进行排序。同样,推荐系统也需要经过规则干预步骤后,才会将最终结果展示给用户。对于最后一步,用户的各种动作行为,在搜索引擎里,会持续优化排序模型,在推荐系统里,还会持续改进自身的画像。
对以上两图进行总结就是下图,就是想让你们看的第二张PNG(图):
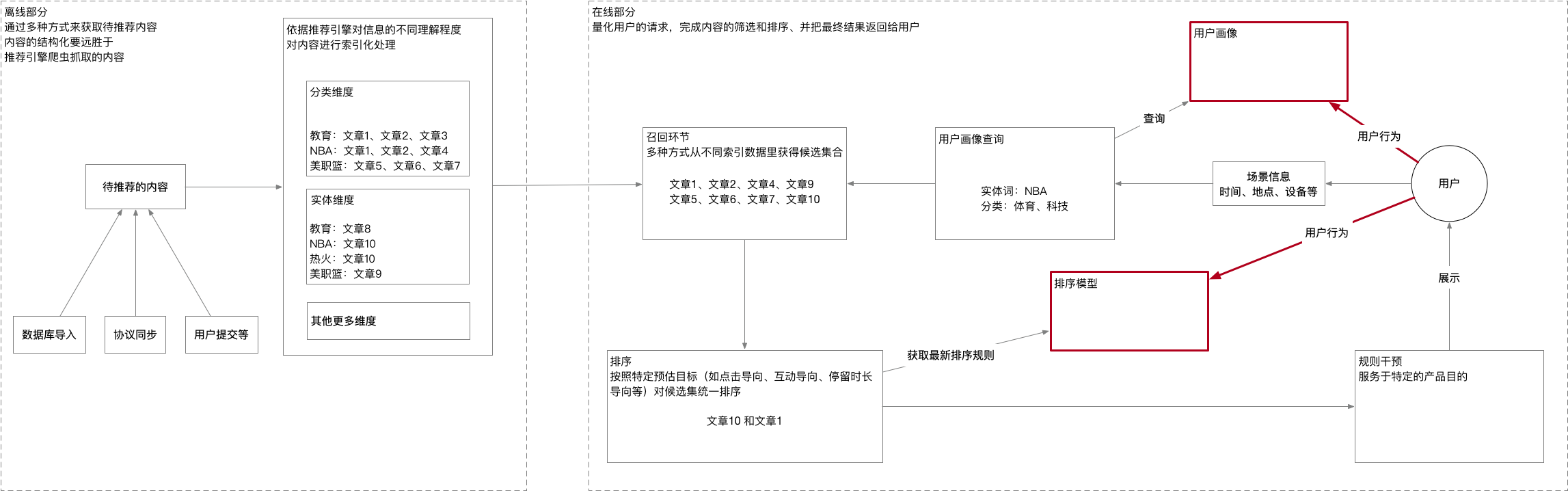
推荐系统的本质
通过对搜索引擎和推荐系统的两张图,我们大致明白了推荐系统是怎么个一回事。实际上,推荐系统是一个策略行为。对于策略,他有四要素,分别是:
待解决问题输入(影响解决方案的因素)计算逻辑(将输入转换成输出的规则)输出(具体的解决方案)
对于今日头条来说:
它待解决的问题是“从海量的内容中,找到用户喜欢的内容”;
他的输入是“用户画像和内容特征”;
计算逻辑:将这些内容特征按一定规则转化为喜欢度;
输出:将内容按喜欢度从高到低排序。
由于我推荐系统的课程还未结束,先不展开这部分内容了。后面博客会对上文进行展开,有兴趣的同学,欢迎关注。
说明:以上内容来源于个人阅读和付费课程的归纳整理。
作者:皮带
来源:皮带
